Did you know that you can navigate the posts by swiping left and right?
Brocxi - Just another RAG-ed application! (Part 1)
24 Apr 2024
. category:
LLM, Deep Learning
.
Comments
#RAG
#LLM
This post contains a walkthrough of techniques I experimented with from different options available to create RAG application.
Brocxi is supposed to be an assistant who specializes in specific games. You can ask Brocxi about different aspects of that game, characters, lore, strategies, and so on.
Right now Brocxi only specializes in God of War Ragnarok
It retrieves content from IGN's guides for the game
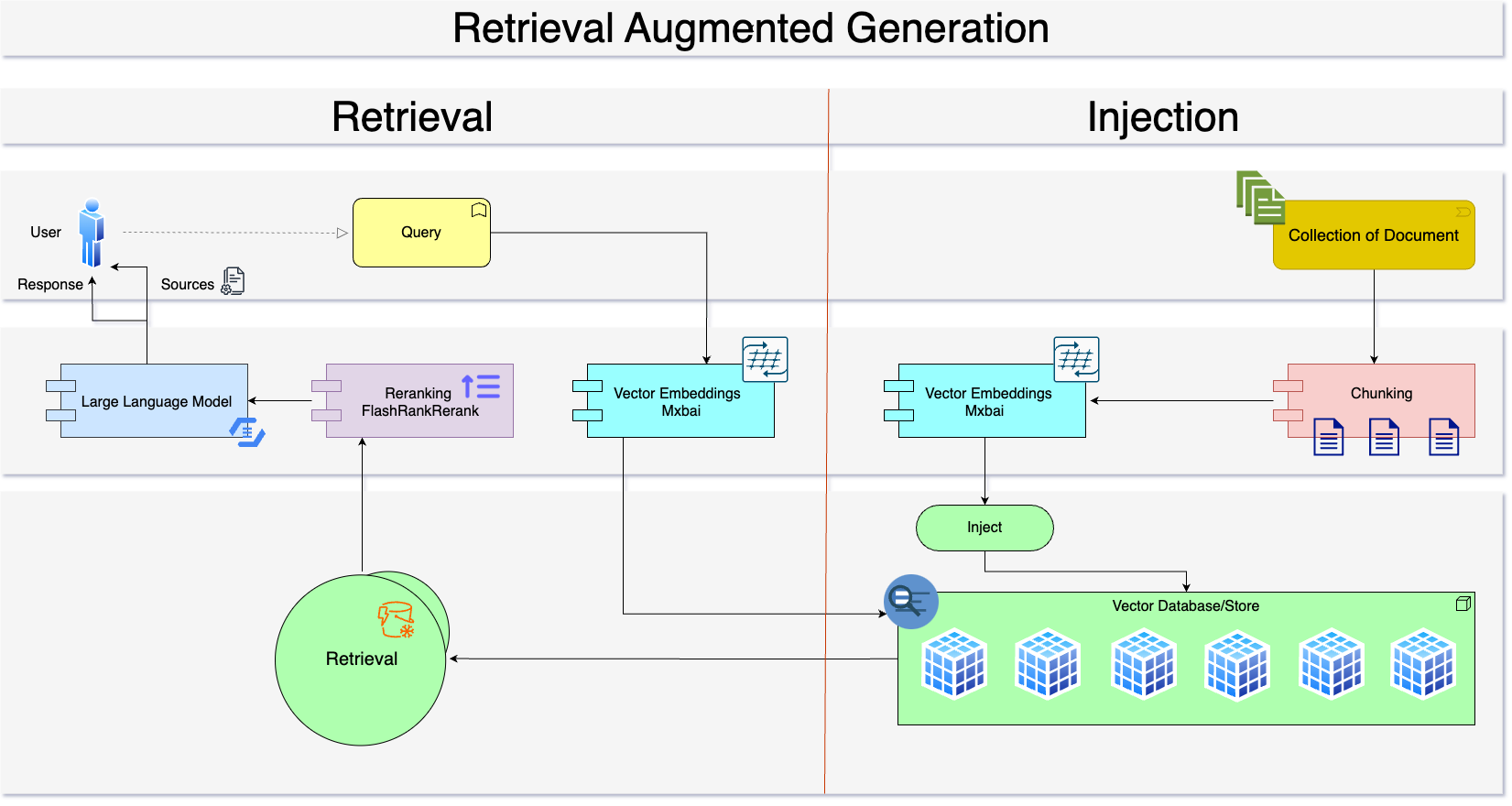
RAG (Retrieval Augmented Generation):
Retrieval Augmented Generation is an additional process/step before passing the query to any LLM to refine the prompt based on most similar contents with the current query. We use something called vector databases to store the documents in vector-embedded format. We also need a document base to embed and store in a vector database. These are the documents that contain relevant information regarding the problem you are trying to solve. For instance, you are trying to make a Customer Service Representative chatbot for your company. In this case, the document base will be your company’s data like policies, compliance, health & safety documents, and so on. When a user asks something about the company’s specific policy we can fetch the most relevant documents and pass it as a context to an LLM. It will not be practical to pass the whole policy file to LLM’s context because of the context window limitations in LLMs. So, we only pass the K most relevant chunks of texts.
WHY RAG?
LLMs tend to Hallucinate(Confabulate) which means they generate texts with false information and are confident about its factfulness. If you ask an LLM about your company data or data that was not trained on, it does not know about it. There are two options to solve this right now, fine-tuning and RAG. The fine-tuning tuning process involves retraining the last few layers of an established foundational model to make it aware of your specific data. This process is costly and resource-heavy because we have to deal with a large number of parameters to make the model remember our data. RAG tries to provide that context to the LLM so that it generates the right information instead of making things up. To avoid re-training large foundational models, I have decided to use the RAG approach for Brocxi.
RAG Components:
- Document Loading & Chunking
- Vector Embeddings Generation & Injection
- Similarity Search & Retrieval
- Rerank
- Synthesis
Process Flow:
I have used LangChain for this task and found the documentation extremely helpful and easy to navigate around for exploring different options available for RAG applications
Document Loading & Chunking
The initial phase is the loading phase. At first, a collection of all the guides related to God of War Ragnarok from IGN was collected and put in a directory.
Loader:
DirectoryLoader from LangChain was used to load the documents in a directory.

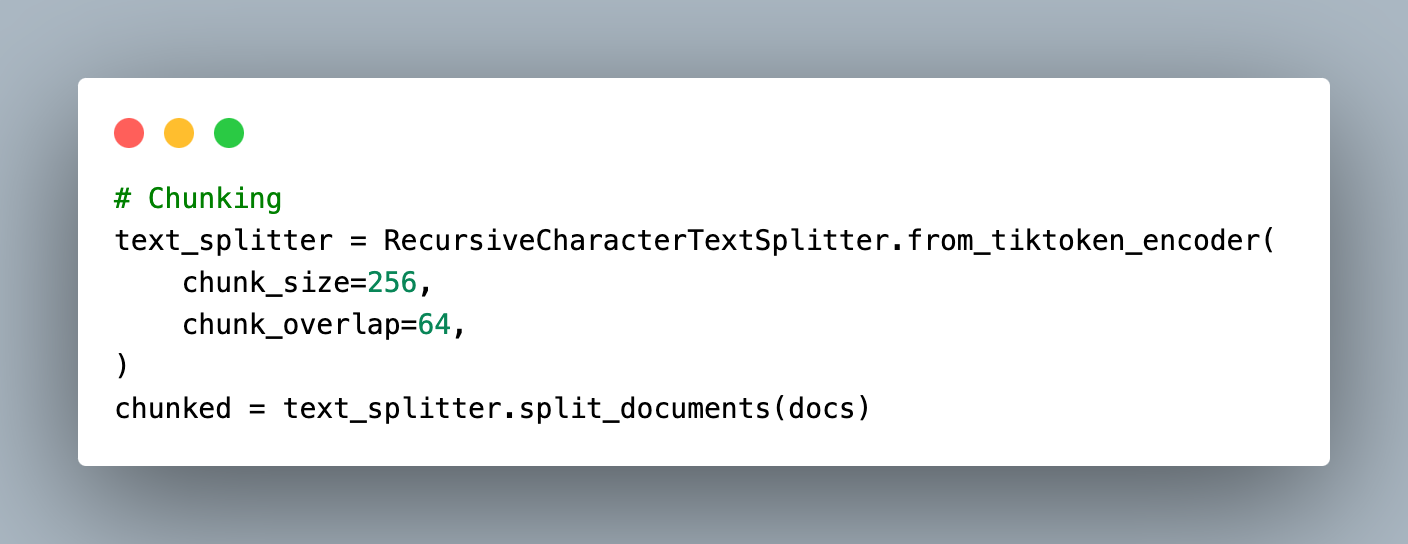
Chunking:
The document texts needed to be split into a certain number of chunks to be stored in the vector database. There are many strategies to strategically chunk documents but for the sake of simplicity, I have used simple RecursiveCharacterTextSplitter.from_tiktoken_encoder with a chunk size of 256 each with an overlap of 64. It does not allow the split size to be larger than 256 in this case. Each consecutive chunks have the same last and first 64 characters to retain the context.
Vector Embeddings & Injection :
The reason we convert texts into arrays of vector embeddings here is to perform similarity search algorithms. These vectors are just a bunch of numbers between 0 and 1. After converting them into vectors, they reside in a latent space in something called a vector database. A set of similar vector collections reside closer to each other forming clusters of semantically similar sentences. The process of placing these embedded vectors into a vector database is known as Injection.
Embedding Algorithm:
There are many embedding algorithms to choose from. I tried OpenAIEmbeddings and CohereEmbeddings to generate embeddings for Brocxi where CohereEmbeddings performed better under the same settings. But the problem is these are APIS. I wanted to try and run them locally. I was exploring HuggingFaceEmbeddings and came across MTEB Leaderboard.
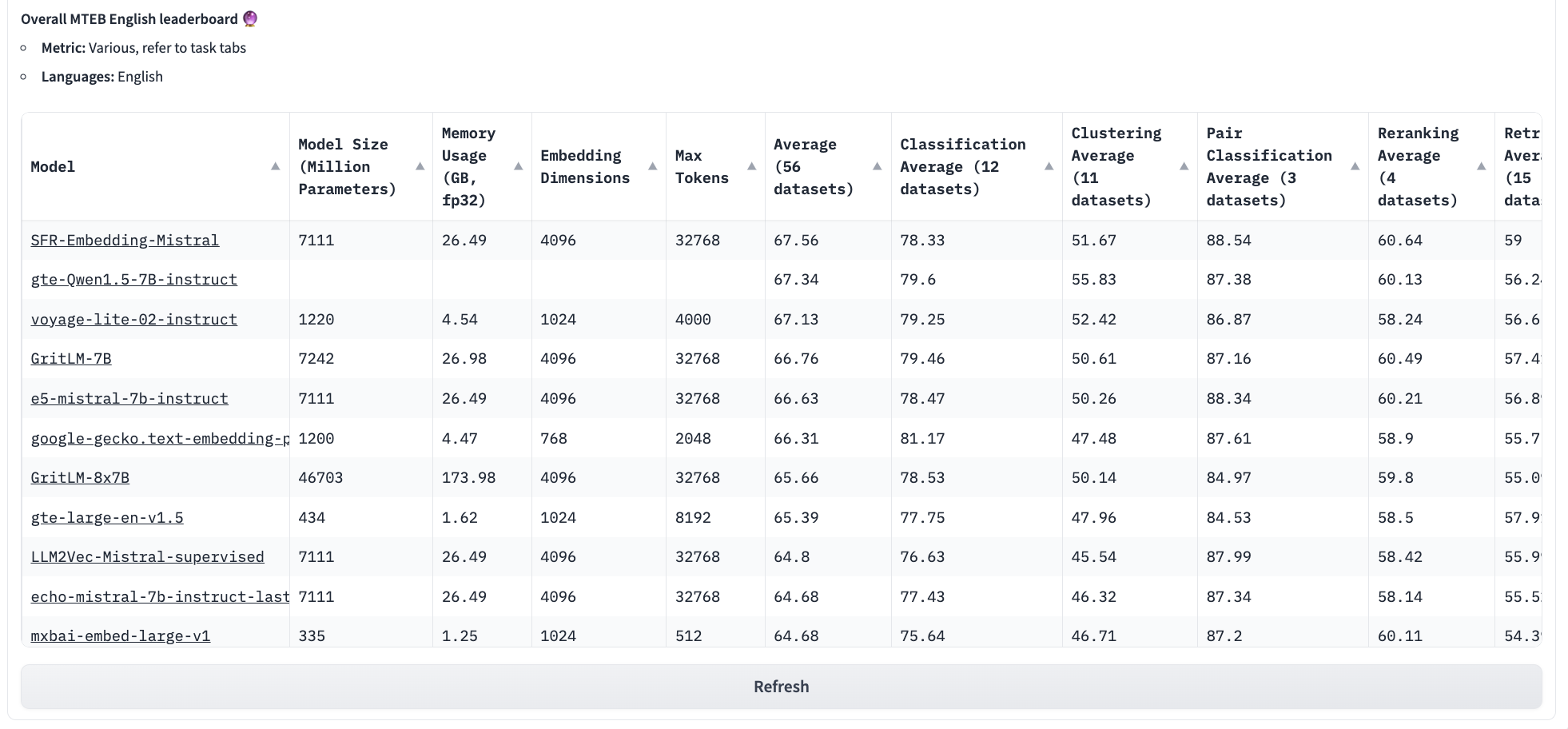
The mixedbread-ai/mxbai-embed-large-v1 embeddings caught my eye as they had massively less memory usage with fewer parameters and dimensions but had similar performance on different metrics. We can use this embedding model to embed our text chunks and also to embed the user’s query later during inferencing.

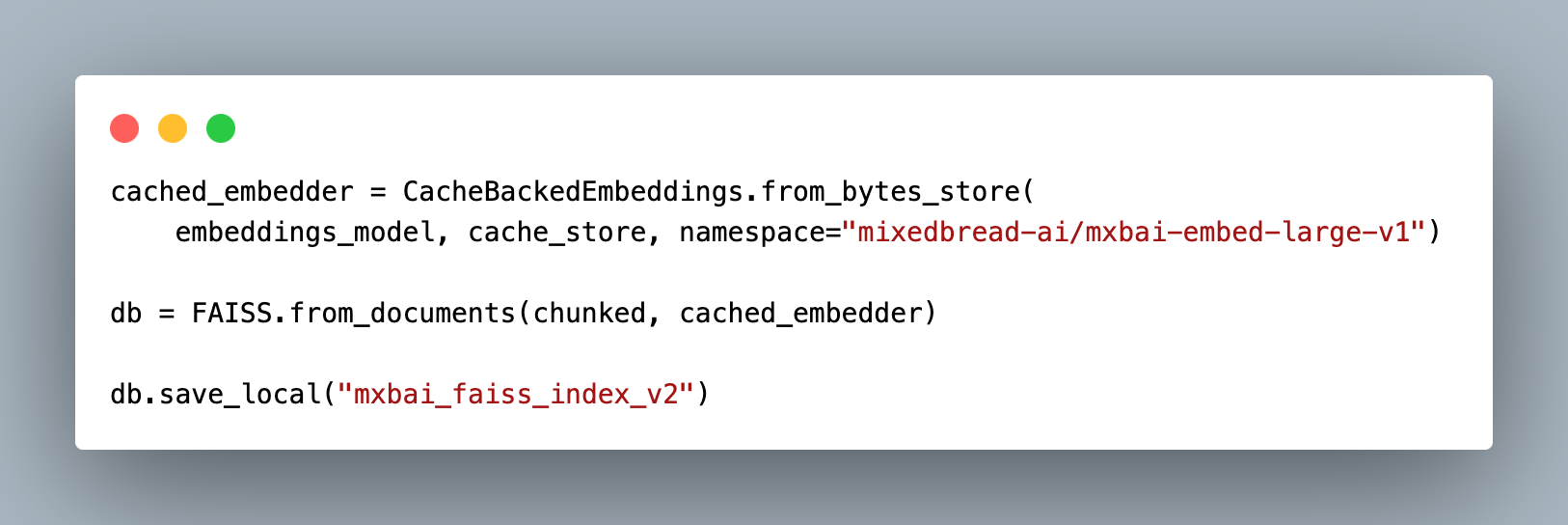
Vector Database, Caching & Injection :
We can cache the generated embeddings as key-value pairs before injecting so that we do not have to recalculate the embeddings for each chunk each time. LangChain’s CacheBackedEmbeddings.from_bytes_store can be used to construct these key-value stores. These cached embeddings can then be passed while initiating the vector database. I have used Facebook AI Similarity Search (Faiss) embeddings. It uses dense vectors for semantic similarity search. Sparse vectors do not capture the true meaning of the words so two sentences have different meanings but the same words will match if we use sparse vectors. For example: “The cat is bigger than the mouse” and “The mouse is bigger than the cat” will be represented as the same sentences if we use sparse vectors. More about these later but here I have used the FAISS as the vector database. It also has the save_local method which can be used to save the embeddings locally.
Similarity Search & Retrieval :
This is where we filter out all the texts from a set of documents and then only select a few relevant text chunks. We need a retriever for this and we will take out FIASS vector db as our retriever. We load the db as a set retriever as db.as_retriever(). This acts as our base retriever for the chunks that will be passed to the LLM with the user query. There are many other available vector stores like Pinecone, Weaviate, ChromaDB, and so on.
Reranking :
The extracted chunks might not be sorted in the most relevant order to the user query and when we select the top k chunks, some important chunks might be ignored. Even if all of the unsorted important information is passed to the LLM as its context, the LLMs are better at using the relevant information that occurs at the very beginning of the context or at the very end of the context. They ignore some important relevant documents in the middle of the context. This problem is called the Lost in the Middle problem.
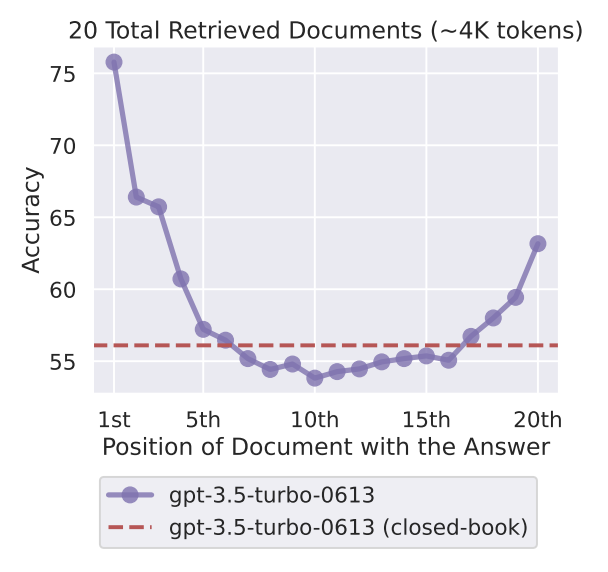
To mitigate this we can leverage Reranking systems. There is one Reranking algorithm API by Cohere called CohereRerank() which is very good but I wanted to go for a local approach and use FlashrankRerank() which also has very good performance and speed. The re-ranker and the retriever are then passed into a ContextualCompressionRetriever which will use a compressor that is our reranker to sort the document before sending it as context.
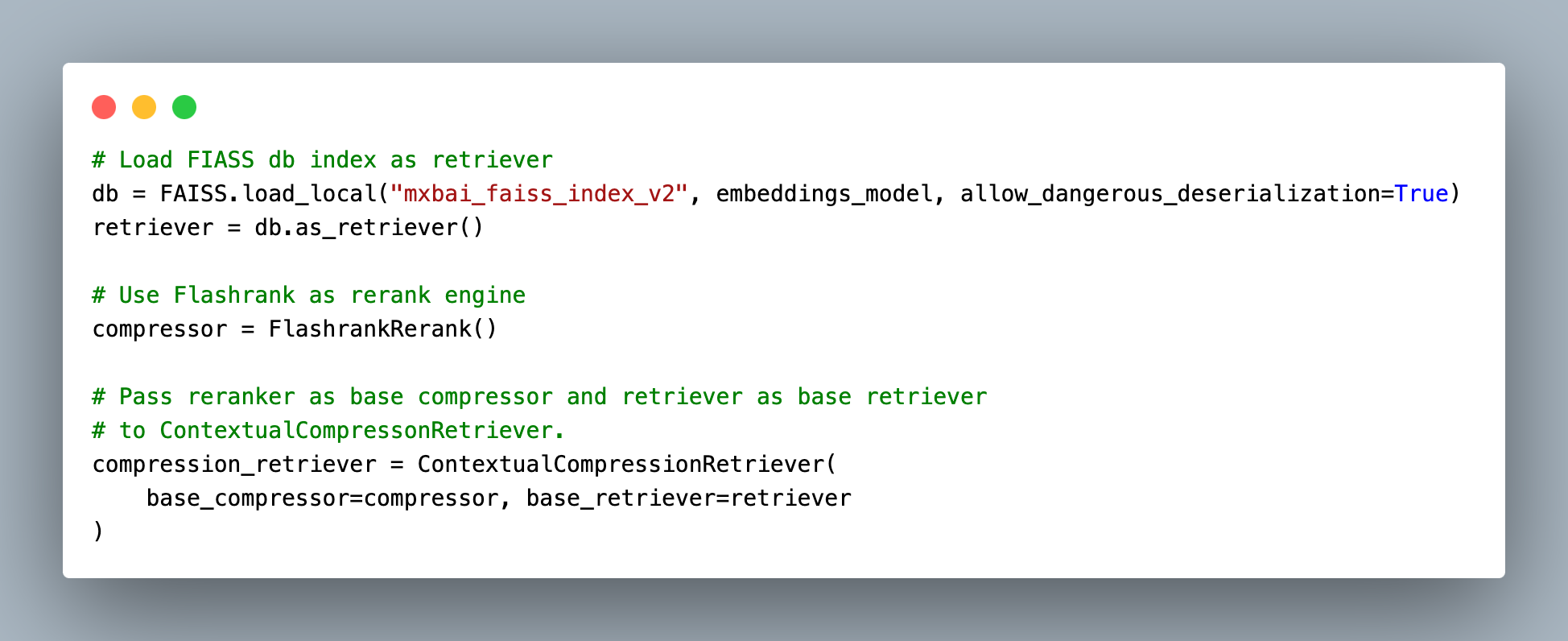
Synthesis :
After retrieving and reranking the document chunks, we need to give the information back to the user as readable and coherent responses. We can use any LLM here, it will take the documents and then synthesize the context of the documents to generate the final response. After trying OpenAI, Cohere, and Mistral, I ended up using Llama3 by Meta and I will test on Phi-3 as well because these are more recent approaches to open-source LLMS. I tried using CTransformers library but it did not have support for llama3. But it can be run with LlamaCpp.
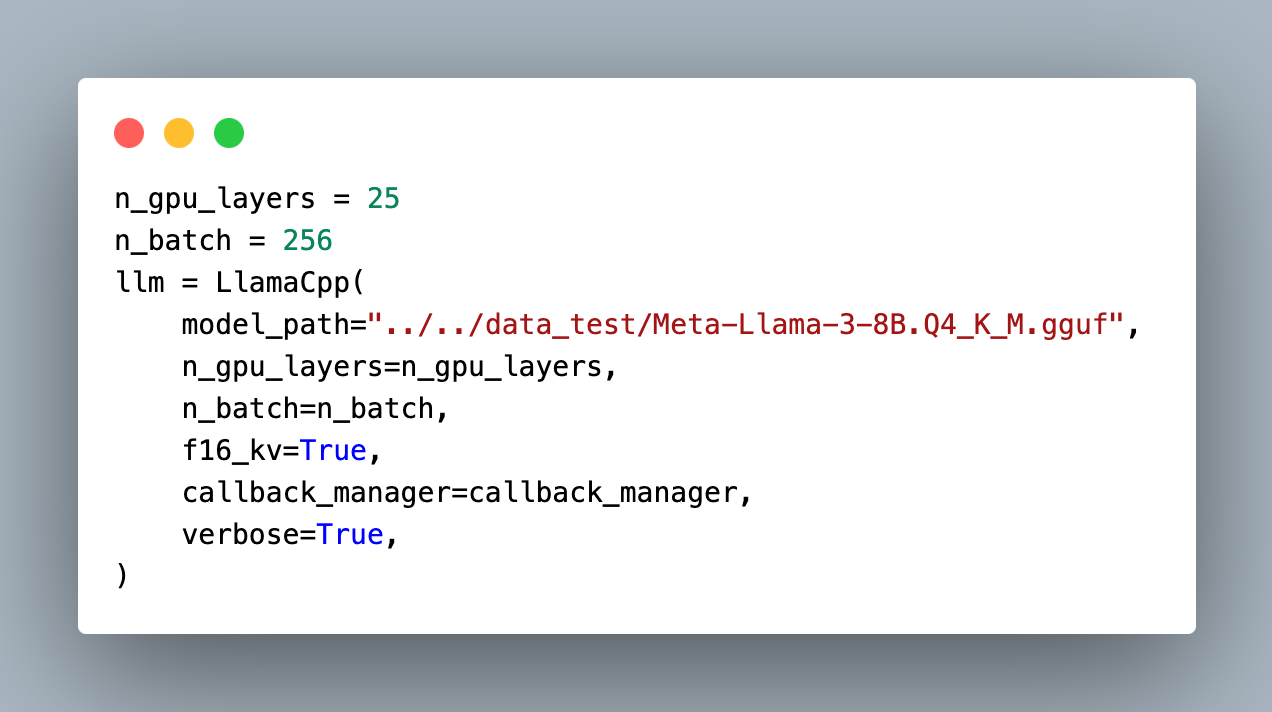
It can also be used via Ollama.

Chainlit App:
Chainlit is a fantastic tool to create chatbots in no time. Let’s define Message history, chat memory, and our conversational retrieval chain in the on_chat_start function.

Then, we can just start the chat session, and initialize the callback handler and async chain. We can also return the source documents with the answer.

Results:
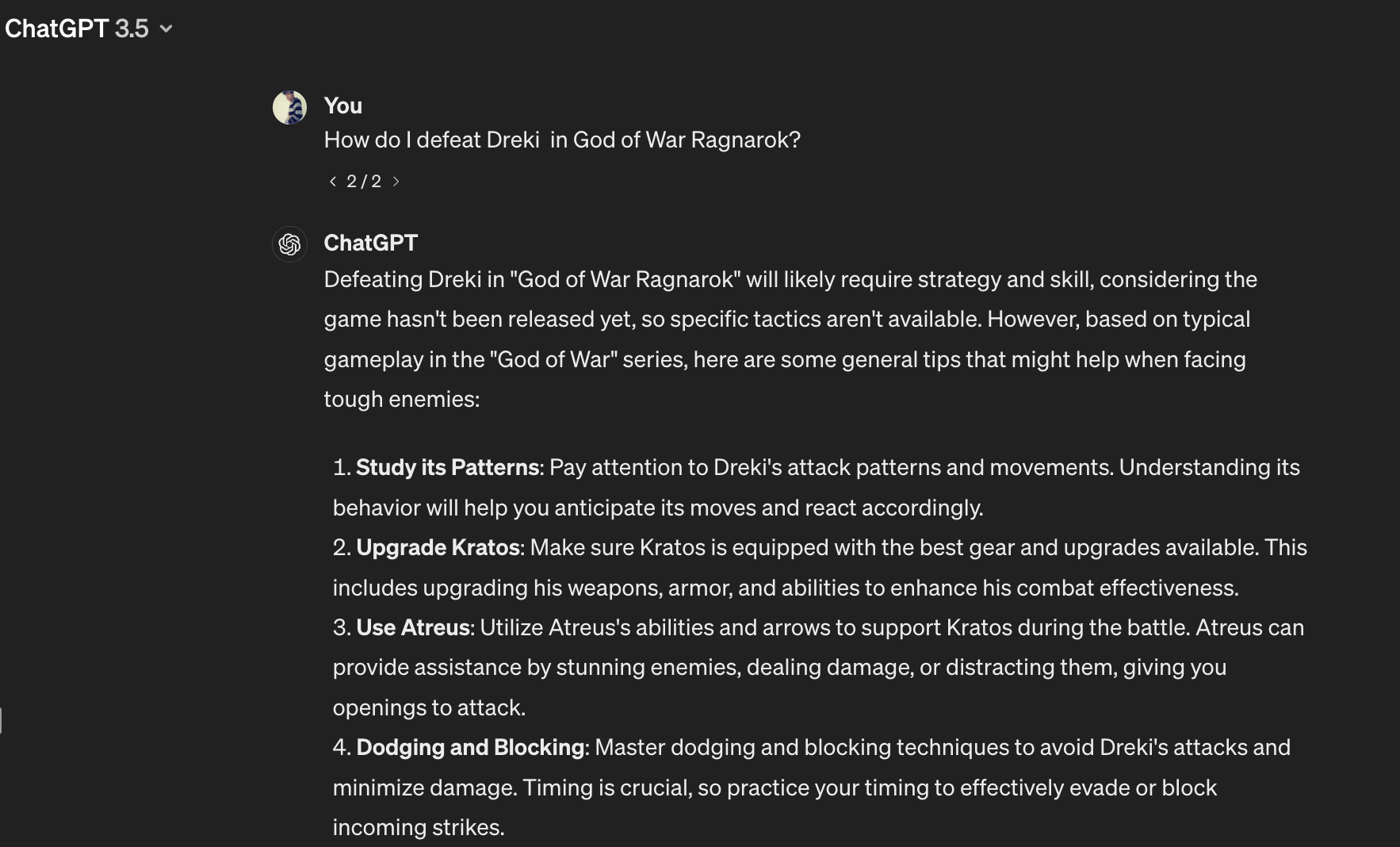
Without RAG:
The bot seems to give generic information on defeating this dragon creature Dreki. Things like Look for openings, Use your abilities wisely, Stay patient and persistent, and so on.
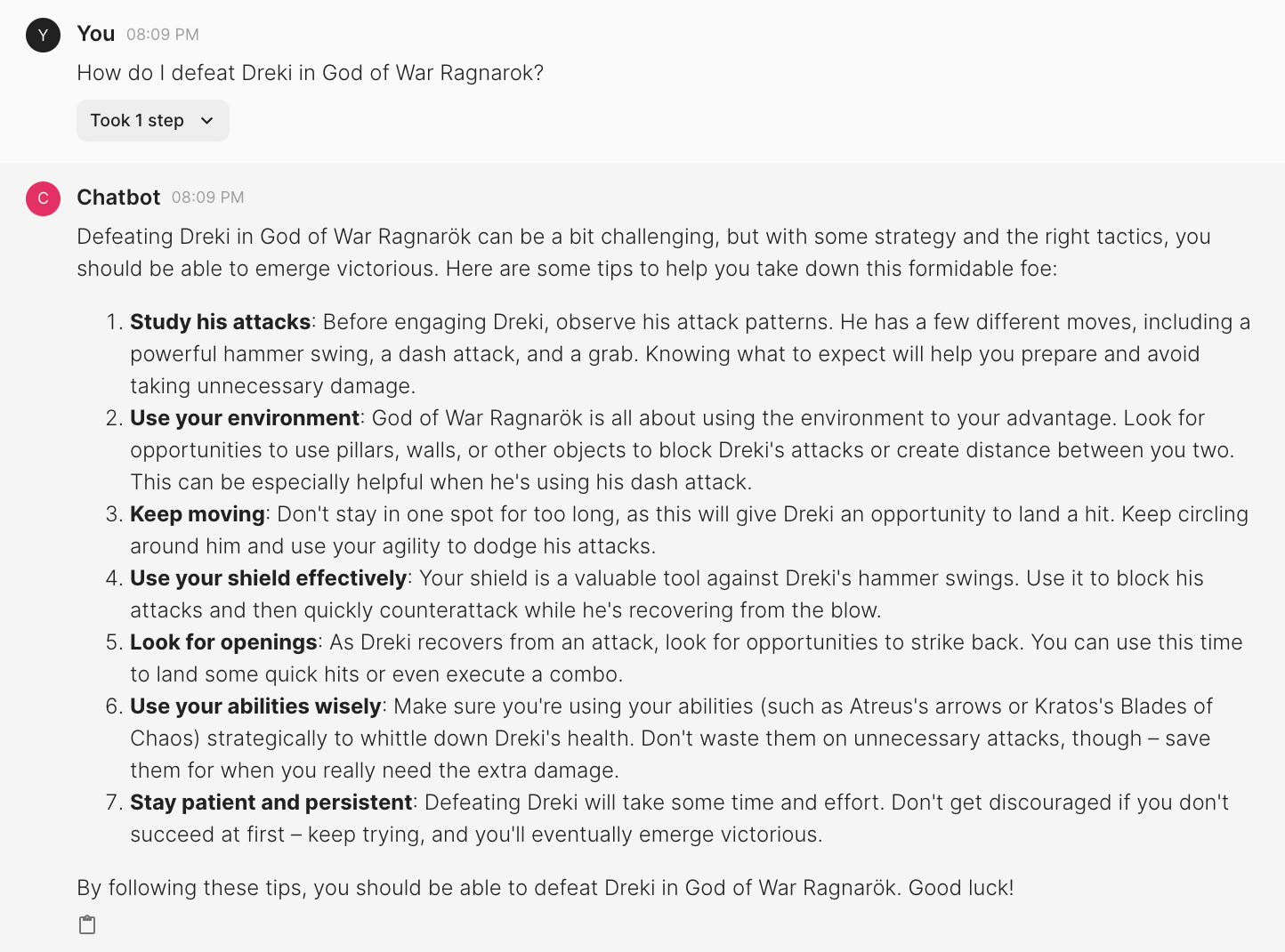
GPT3.5
Since the game was not released at the time when GPT3.5 was trained, it says that the game has not been released yet and starts giving general suggestions.
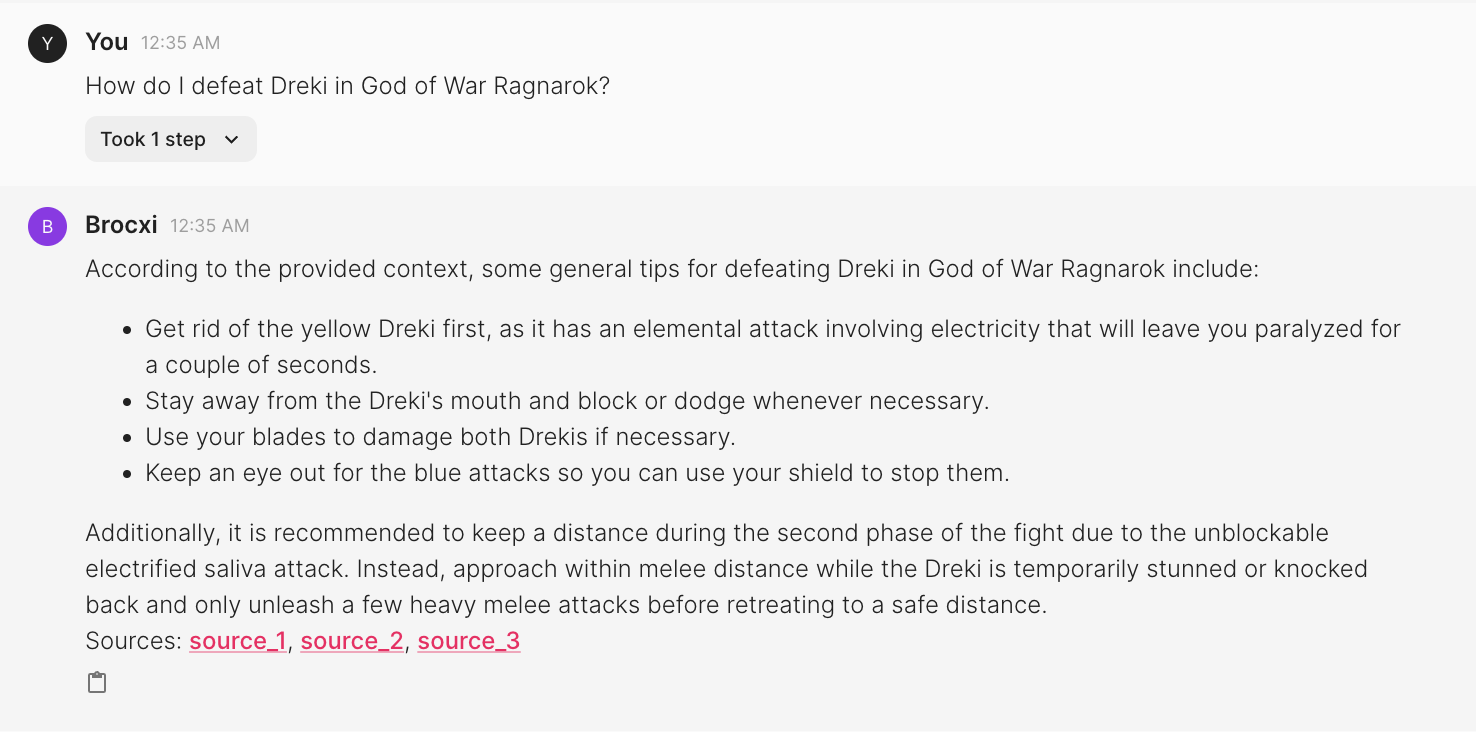
RAG-ed
After applying the RAG approach, the bot was specific about defeating the Dreki. I like how it highlights the fact there are two Drekis and one should kill the yellow one first. It also warns about the electrified saliva attack which deals the most damage to Kratos and is kind of a big deal in Dreki’s fight.

If you want to experiment with Brocxi, feel free to use this repo and README.md to set it up locally.
TODO:
- Evaluation using RAGAS.
- Get more quality data for embeddings. Seems like, just the IGN guide was not enough because players will ask about lores and other stories. As for the side mission with giant jellyfish, the IGN guide does not mention the word “jellyfish” because its name is Hafgufa. Need to include fandom wikis, gamefaqs, and other guides as well. Experiment with different retrieval techniques and use a larger version of Flashrank rerank.
- Another Retrieval method: ParentDocument, Long-Context Reorder??
Resources:
- https://cs.stanford.edu/~nfliu/papers/lost-in-the-middle.arxiv2023.pdf
- https://github.com/PrithivirajDamodaran/FlashRank
- https://python.langchain.com/docs/get_started/introduction/
- https://medium.com/@tejpal.abhyuday/retrieval-augmented-generation-rag-from-basics-to-advanced-a2b068fd576c
- https://ollama.com/library
- https://docs.chainlit.io/integrations/langchain

My way of doing things might not be perfect, so I am always open to suggestions. Feel free to contact me for queries regarding any post or if you have any suggestion for me, through the contact section.